What Comes After LLMs? $24 Billion Says Next-Token Prediction Is Not the Final Answer.

President, Zaruko
Table of Contents

This series has argued, across four posts, that large language models predict tokens through sophisticated pattern matching, not through grounded world models, causal models, or formal symbolic inference. That inference-time search with a verifier can extend those capabilities for structured problems. That training-time advances improve outputs without changing the underlying architecture. And that the practical implication is to design for verifiability rather than reasoning.
The final question the series has been building toward: is the next-token prediction architecture permanent, or is the research community working on something different?
The answer is both. LLMs will dominate applied AI for several more years. The research community is already building alternatives. The investment flowing into those alternatives has accelerated sharply in the past six months.
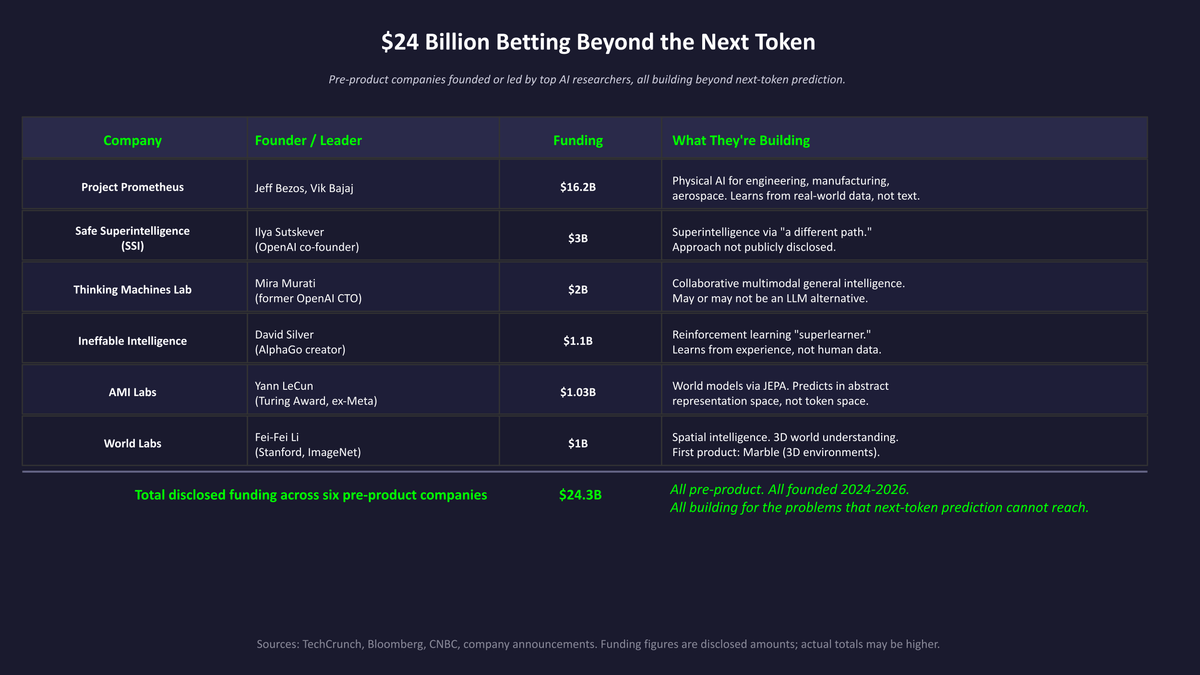
Figure 1: $24 billion in disclosed funding across six pre-product companies, all betting beyond next-token prediction.
Why Researchers Are Looking Beyond Next-Token Prediction
The concern is not that LLMs are useless. They are clearly useful. The concern is that they may have a structural ceiling on what they can do.
The Apple GSM-Symbolic results, discussed in the first post of this series, showed that leading models can fail when irrelevant information is added to a math problem. Scaling has reduced some of these failure modes but has not eliminated them. Sensitivity to surface variation decreases with scale, at considerable cost, but the fragility remains. That is why serious researchers are exploring different architectures.
A second structural concern is that next-token prediction has no grounded model of the world. The model learns statistical relationships between tokens, not physical relationships between objects and events. This is why models hallucinate with confidence: they are not retrieving facts from a grounded knowledge structure, they are completing patterns from training data. When the pattern leads to a false completion, there is no internal mechanism that reliably catches it.
A third concern is efficiency. The attention mechanism in standard transformers scales quadratically with sequence length. Doubling the context window roughly quadruples the computation required to process it. This is manageable at current scales but becomes increasingly costly as applications demand longer contexts and more complex reasoning chains.
These three concerns, fragility to surface variation, lack of physical grounding, and quadratic scaling costs, are each being addressed by different research directions.
World Models: Learning What Happens, Not What Words Come Next
The most prominent alternative is the world model approach associated with Yann LeCun, who left Meta in December 2025 after twelve years to found AMI Labs, where he is now chairman.1
LeCun's core argument, published in a 2022 paper called "A Path Towards Autonomous Machine Intelligence," is that next-token prediction is the wrong objective.3 A model trained to predict text learns the statistical structure of text. It does not learn the physical structure of the world. A world model, in his framing, should predict what happens next in the physical world, not what word comes next in a sentence. It should build an internal representation of objects, their properties, and the ways they interact.
The architecture he proposed is called the Joint Embedding Predictive Architecture, or JEPA. The key difference from next-token prediction is where the prediction happens. In an LLM, the model predicts in the space of tokens: it predicts which word comes next. In a JEPA model, the model predicts in an abstract representation space: it predicts what the world will look like, not what pixels or tokens will appear. By predicting at a higher level of abstraction, the model is forced to learn structure rather than surface.
Meta's research team, before LeCun's departure, published V-JEPA 2, a world model trained on more than one million hours of video and one million images.4 The model learns to predict how objects move and interact by watching unlabeled video. It achieves strong performance on physical reasoning benchmarks and can plan actions for a robot arm in environments it has not seen before, without any additional fine-tuning. LeCun's new company, AMI Labs, raised $1.03 billion in seed funding in March 2026 to pursue commercial applications of this approach, particularly in robotics, industrial control, and healthcare.1
LeCun is not alone. Fei-Fei Li, the Stanford professor often called the "godmother of AI," founded World Labs, which raised $1 billion in February 2026 from investors including AMD, Autodesk, NVIDIA, and Fidelity.2 Li and Prof. Kai Li of Princeton were co-Principal Investigators on the ImageNet project, the large-scale visual dataset that helped launch the modern deep learning era. World Labs is focused on "spatial intelligence," AI systems that understand how three-dimensional space works. Their first product, Marble, generates persistent, editable 3D environments from text, images, or video, targeting gaming, visual effects, robotics, and scientific discovery. Together, AMI Labs and World Labs represent over $2 billion in disclosed funding for world model research in early 2026 alone.
The honest assessment: world models are promising for domains where physical grounding matters. They are not yet competitive with LLMs on language tasks. The gap may close, but the timeline is measured in years, not months. AMI Labs' CEO acknowledged as much at launch: this is fundamental research, not a product that ships in six months. The V-JEPA 2 technical report provides detailed benchmarks on physical reasoning and robot planning tasks.5
Primary use case: Robotics, industrial automation, physical simulation, and any domain where understanding how objects move and interact matters more than generating text.
Strength: Learns physical regularities from observation rather than statistical patterns from text. Can plan actions in controlled physical environments it has not seen before.
Weakness: Not yet competitive with LLMs on language tasks. The approach requires large amounts of video training data. Commercial applications are years away from production.
Reinforcement Learning at Scale: Learning from Experience, Not Data
A closely related but distinct approach to world models is reinforcement learning at scale: systems that aim to learn primarily from interaction, simulation, trial-and-error, and self-play, rather than from static human-generated text corpora.
Ineffable Intelligence, founded by David Silver, raised $1.1 billion in seed funding in April 2026 at a $5.1 billion valuation.19 Silver spent over a decade leading DeepMind's reinforcement learning team, where he built AlphaGo (the first AI to defeat a world champion at Go), AlphaZero (which mastered Go, chess, and shogi through pure self-play without any human data), and AlphaStar. Ineffable's thesis is that LLMs are fundamentally limited because they learn exclusively from human-generated data, which means they can remix existing knowledge but cannot discover something entirely new. Reinforcement learning, by contrast, allows a system to learn from trial, error, and self-play, producing strategies no human has conceived. AlphaGo's famous Move 37 against Lee Sedol was not in any human game record; it was discovered by a machine learning beyond human intuition.20
Ineffable is building what it calls a "superlearner" that discovers knowledge from its own experience, not from text. This is not next-token prediction. It is a fundamentally different learning objective: maximize a reward signal through interaction, rather than minimize prediction error on a static dataset.
Primary use case: Domains where the solution space is too large for human expertise to cover, and where the system can learn through simulation or interaction: scientific discovery, materials design, drug discovery, strategic planning, and mathematical reasoning.
Strength: Can discover novel solutions that no human has conceived. AlphaZero proved this is possible in constrained domains. Does not depend on the quality or coverage of human-generated training data.
Weakness: Requires a well-defined environment and reward signal, which limits applicability to domains where outcomes can be simulated or measured. Scaling from board games to open-ended real-world problems remains an open research challenge. No product or public roadmap.
Physical AI: Learning from the Real World
Project Prometheus, co-founded by Jeff Bezos and former Google X scientist Vik Bajaj in November 2025, represents the largest single investment in post-LLM AI research. The company launched with $6.2 billion and closed a $10 billion follow-on round in April 2026, bringing total funding to over $16 billion at a $38 billion valuation. JPMorgan and BlackRock are among the investors.21
Prometheus is building what the industry calls "physical AI": systems that learn from real-world experimental data, robotics interactions, and engineering workflows rather than from text. The company's thesis is that LLMs, trained on publicly available text and images, cannot understand how the physical world actually works. Physical AI requires a different kind of training data, data that is scarce, proprietary, and expensive to collect, which creates both a barrier to entry and a potential long-term advantage.
The company has hired over 120 researchers, many recruited from OpenAI, DeepMind, Meta, and xAI. Unlike the other companies on this list, Prometheus is also building a broader industrial strategy: Bezos is reportedly seeking additional funding to acquire engineering and manufacturing companies whose operational data would feed Prometheus's models.22
Primary use case: Engineering, manufacturing, aerospace, automotive, robotics, and drug discovery. Any domain where AI needs to understand physics, materials, and real-world processes.
Strength: Backed by the largest disclosed funding of any early-stage AI company. Access to scarce industrial data through planned acquisitions. Physical AI addresses a domain that LLMs cannot touch.
Weakness: The sheer scale of the investment creates high expectations. No product or public demonstration yet. The approach depends on acquiring proprietary data that may be difficult to integrate across industries.
Neurosymbolic AI: Combining Pattern Matching with Explicit Rules
A second approach addresses the fragility problem by combining learned pattern matching with explicit symbolic reasoning.
The concern with pure neural approaches, including LLMs, is that they learn correlations from data but cannot reliably apply logical rules to novel inputs. The concern with pure symbolic AI, the kind that dominated research before deep learning, is that it requires explicit encoding of all relevant rules and cannot generalize from examples the way neural networks can.
Neurosymbolic AI tries to combine both. A neural component handles perception and pattern recognition, the things neural networks do well. A symbolic component handles formal reasoning, the things neural networks do poorly. The two systems interact: the neural component interprets input and produces structured representations, and the symbolic component applies rules to those representations to reach conclusions that hold reliably.
This approach is more mature than world models in some narrow domains. Applications in formal verification, automated theorem proving, and structured data extraction have produced results that outperform pure neural approaches. The MIT-IBM Watson AI Lab has been a leading research center for this work, and Amazon has applied neurosymbolic methods to its warehouse robotics and shopping assistant systems.7 The challenge is that the interface between the neural and symbolic components is difficult to design for general-purpose tasks. Getting the two systems to interact correctly requires domain-specific engineering that does not generalize automatically.
Primary use case: High-stakes domains where explainability and rule compliance are required: healthcare diagnostics, legal reasoning, compliance, formal verification, and safety-critical autonomous systems.
Strength: Produces transparent, auditable decisions. Can enforce hard constraints that neural networks alone cannot guarantee. Addresses the hallucination problem by grounding outputs in explicit rules.
Weakness: Requires domain-specific engineering to connect the neural and symbolic components. Does not generalize automatically to new domains. Scaling to the breadth of current LLMs remains an open problem.
Mamba and State Space Models: Addressing the Scaling Problem
The third direction addresses the efficiency problem rather than the reasoning problem directly.
Mamba, published in December 2023 by Albert Gu and Tri Dao at Carnegie Mellon and Princeton, is a selective state space model.6 A state space model, or SSM, maintains a compressed representation of past context rather than attending to every previous token explicitly. The key innovation in Mamba is that the model's state transitions are input-dependent: the model learns to selectively retain or discard information based on what it is currently processing. This allows it to handle long sequences with linear rather than quadratic scaling.
The practical result: a Mamba model with 3 billion parameters outperforms a transformer of the same size on language modeling, while processing long sequences at roughly five times the throughput. For applications that require very long context, such as genomics, audio processing, and codebases with large amounts of context, the efficiency advantage is substantial.
The limitation is that pure state space models sacrifice some of the exact retrieval capability that attention provides. Hybrid architectures combining Mamba layers with selective attention layers have performed well in recent evaluations. The current direction in the research community is toward these hybrid designs rather than pure SSMs.6
SSMs address efficiency, not the reasoning fragility. A Mamba model is still predicting the next token. It is just doing so more cheaply for long sequences. IBM and other organizations are actively investing in SSM-based language models, with hybrid SSM-transformer architectures emerging as a practical middle ground.8
Primary use case: Applications requiring very long context windows: genomics, audio processing, full-codebase analysis, document processing at scale.
Strength: Linear rather than quadratic scaling with sequence length. Five times the throughput of equivalent transformers on long sequences. Hybrid designs combining SSM and attention layers preserve retrieval accuracy while gaining efficiency.
Weakness: Pure SSMs sacrifice some exact retrieval capability. Does not address reasoning fragility or hallucination. Still fundamentally a next-token predictor.
Other Directions Worth Watching
The three approaches above are the most heavily funded and the furthest along. They are not the only ones. Five additional research directions are worth tracking, each addressing a different limitation from a different angle. An important distinction: moving beyond next-token prediction does not automatically solve reasoning. Several of the approaches below change the generation mechanism without addressing the reasoning problem directly. The value of each approach depends on the specific limitation it targets.
Causal AI
Standard machine learning, including LLMs, learns correlations from data. Causal AI learns cause-and-effect relationships: if I do X, what happens to Y? The theoretical foundation comes from Judea Pearl, whose work on causal inference earned the 2011 Turing Award.9 Pearl's core argument is that traditional AI relies on statistical correlations rather than causal inference, which limits its effectiveness in domains where you need to predict the consequences of actions rather than just describe patterns.
The practical difference matters in enterprise settings. A correlation-based model might learn that ice cream sales and drowning deaths both increase in summer and infer a relationship between them. A causal model knows that warm weather causes both, independently. Companies like causaLens are building commercial causal AI platforms, and causal methods are already used in production decision systems at major technology companies, including publicly documented work at Uber on uplift modeling and treatment effect estimation.10
Primary use case: Decision support where you need to know what will happen if you change something: pricing decisions, policy evaluation, intervention planning, root cause analysis.
Strength: Produces answers you can act on with higher confidence because the model distinguishes causation from correlation. Enables counterfactual reasoning: "what would have happened if we had done X instead of Y?"
Weakness: Building causal models still requires domain expertise to define the causal graph. General-purpose causal reasoning at the scale of LLMs does not yet exist. The approach works best when the causal structure is at least partially known.
Energy-Based Models
Instead of predicting the next token, energy-based models assign a compatibility score to pairs of inputs and outputs. Lower energy means better compatibility. The model evaluates how well a candidate output fits the input, rather than generating output one piece at a time. This is closely related to LeCun's JEPA architecture, which is itself a type of energy-based model: JEPA predicts in an abstract representation space and scores predictions by their compatibility with reality.3
Primary use case: Domains where evaluating a proposed answer is easier than generating one from scratch, which connects directly to the verifiability framework from the previous post in this series.
Strength: Can evaluate multiple candidate outputs in parallel rather than generating sequentially. Naturally fits the generator-verifier framework discussed throughout this series.
Weakness: Training energy-based models is harder than training autoregressive models. Scaling them to the size of current LLMs remains an open research problem. Fewer commercial implementations exist compared to other approaches on this list.
Active Inference
Developed by neuroscientist Karl Friston at University College London, active inference is rooted in the Free Energy Principle: the idea that biological systems survive by minimizing the difference between their predictions about the world and what they actually observe.11 An active inference agent does not just predict. It acts to reduce its own uncertainty. It combines perception, learning, and action in a single framework. Friston published a paper in December 2025 extending active inference to artificial reasoning, showing how the framework can be applied to structure learning and hypothesis testing.12 Friston serves as Chief Scientist at VERSES AI, a company building commercial applications of active inference.13
Primary use case: Robotics and autonomous systems where an agent needs to explore its environment, update its model, and take actions in a continuous loop. Also relevant for any system that needs to know what it does not know.
Strength: Provides a principled framework for agents that quantify their own uncertainty and actively seek information to fill gaps. This directly addresses the hallucination problem: an active inference agent can recognize when it lacks sufficient evidence to act and seek more information instead.
Weakness: Computationally expensive and mathematically demanding. Has not yet been demonstrated at the scale or generality of current LLMs. The gap between theoretical elegance and practical deployment remains large.
Diffusion Language Models
Diffusion models transformed image generation (Stable Diffusion, DALL-E). The same principle is now being applied to text. Instead of generating one token at a time from left to right, a diffusion language model starts with a fully masked or noisy sequence and iteratively refines the entire text simultaneously. LLaDA (Large Language Diffusion with Masking), published by researchers at Renmin University of China in February 2025, demonstrated that an 8-billion-parameter diffusion model can be competitive with LLaMA 3 8B on standard benchmarks while using far less training data (2.3 trillion tokens vs. 15 trillion for LLaMA 3).14 A subsequent paper, LLaDA-MoE, showed that a sparse mixture-of-experts diffusion model with only 1.4 billion active parameters can surpass prior 8-billion-parameter diffusion models.15
Primary use case: Tasks where the ability to revise earlier tokens matters: editing, rewriting, and tasks where left-to-right generation introduces errors that cascade. Also relevant for mathematical reasoning, where LLaDA shows particular strength.
Strength: Parallel generation (potentially faster than sequential). Bidirectional context (the model sees both sides of a gap). Reports better performance on a reversal-correction benchmark, including a reversal poem task where it surpassed GPT-4o. Uses significantly less training data to reach comparable performance.
Weakness: Early-stage technology. Requires many refinement steps for high quality output. Efficiency gains over autoregressive models have not yet been fully realized at production scale. No major commercial deployment yet.
Large Concept Models
Meta's Large Concept Model, published in December 2024, represents the most radical departure from next-token prediction on this list.16 Instead of predicting the next token, LCM predicts sentence-level semantic representations, which Meta calls "concepts." The model operates in SONAR, a language- and modality-agnostic embedding space that, through SONAR's encoders and decoders, supports over 200 languages in text and 76 languages in speech.17 A 7-billion-parameter LCM outperformed LLaMA 3.1 8B on zero-shot multilingual summarization.
Primary use case: Long-form content generation, summarization, and multilingual tasks where operating at a higher level of abstraction than individual tokens improves coherence and efficiency.
Strength: Concept-level prediction reduces sequence length compared to token-level processing, which helps with long contexts. The language-agnostic design enables strong zero-shot cross-lingual transfer without retraining. The architecture is explicitly connected to LeCun's JEPA vision for reasoning in abstract representation spaces.
Weakness: Has not yet been benchmarked on standard tasks like MMLU or coding. Sentence-level granularity may lose fine-grained information. The architecture is still in the proof-of-concept stage, and current results on standard benchmarks do not yet match flagship LLMs.
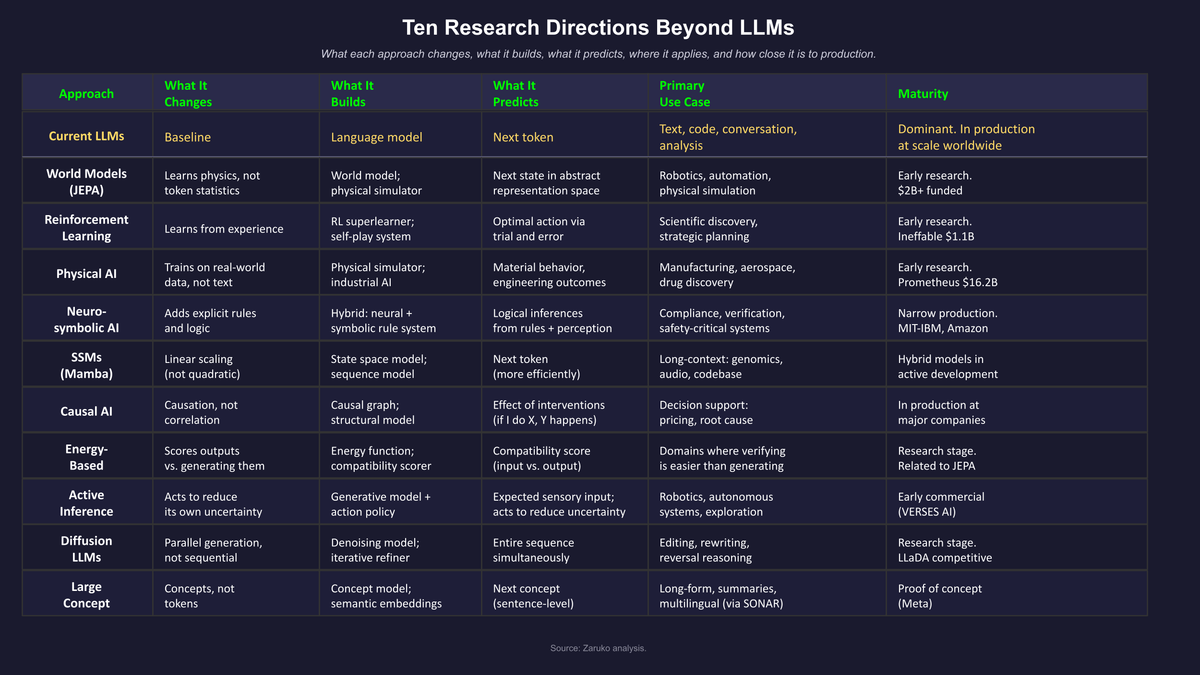
Figure 2: Ten research directions addressing different limitations of the next-token prediction approach.
Where Might More Reliable Reasoning Come From?
This series argued across four posts that LLMs do not reason through grounded world models, causal models, or formal symbolic inference. They predict tokens. That raises the question this post should address directly: where might more reliable reasoning come from?
The honest answer is that general-purpose reasoning remains one of the oldest unsolved problems in artificial intelligence. The challenge is not computation. It is knowledge representation: how do you encode what a system knows about the world in a form that supports inference? Marvin Minsky's frames (1974), Roger Schank's scripts, and the CYC project all attempted to solve this. None succeeded at scale. The difficulty is not representing any single fact, but representing the vast web of implicit knowledge that humans use without thinking: that dropped objects fall, that people have intentions, that time moves forward.18
Three of the eight architectures in this post represent partial paths toward reasoning, each attacking a different piece of the problem.
World models are the most direct path. If you build a system that learns how the physical world works by observing it, that system can simulate "what happens if I do X?" in abstract representation space. LeCun has explicitly framed this as a prerequisite for reasoning: in his view, reasoning is planning in representation space, and planning requires a world model.3 V-JEPA 2 demonstrates this in narrow physical domains, where the model can plan robot actions in environments it has not seen before.45 The gap between planning a robot arm movement and reasoning about a legal contract is enormous. But the broad principle is similar: simulate possible outcomes and evaluate them.
Neurosymbolic AI is the most traditional path. Symbolic reasoning through formal logic is well understood and has been since the 1950s. The hard part is connecting symbolic rules to perception and natural language. Systems that bridge this gap already work in narrow domains: automated theorem provers like Lean and Coq can verify mathematical proofs, and hybrid systems can enforce compliance rules against natural language documents. The limitation is that every new domain requires new engineering to define the symbolic layer.
Causal AI addresses a specific but important form of reasoning: understanding cause and effect. Judea Pearl's causal hierarchy, seeing, doing, and imagining, maps directly to levels of reasoning capability.9 Current causal AI handles the first two (observing correlations and predicting the effects of interventions). The third level, counterfactual imagination ("what would have happened if we had done something different?"), is where causal reasoning connects to the broader reasoning problem.
None of these approaches solves general-purpose reasoning. Each solves a piece of it. The knowledge representation problem, how to encode the commonsense understanding that humans acquire effortlessly and machines cannot yet represent, remains the fundamental bottleneck. Whether that bottleneck yields to world models learning physical intuition from video, to neurosymbolic systems bridging perception and logic, to causal graphs encoding interventional knowledge, or to some combination of all three, is the defining open question in AI research today.
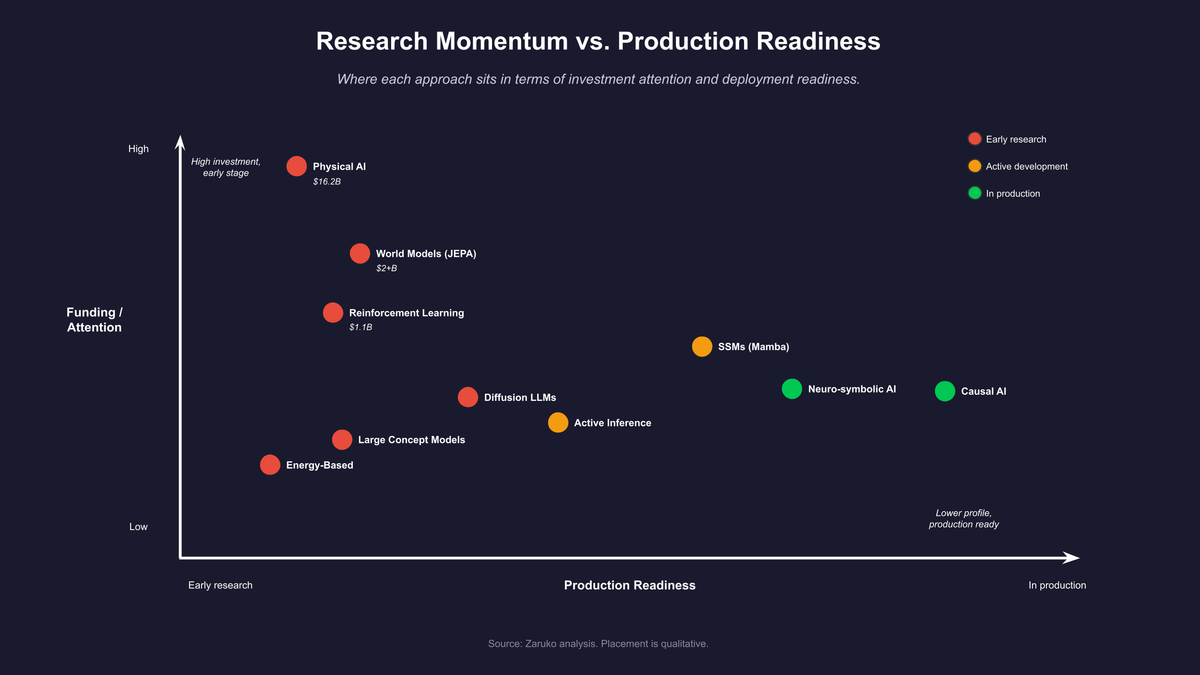
Figure 3: Where each approach sits in terms of investment momentum and production readiness.
What This Means for Enterprise Decision-Making
Three observations for the reader who has followed this series and now wants to know what to do with it.
First: LLMs are not going away. The four posts in this series were not an argument against using AI. They were an argument for understanding the mechanism well enough to deploy it correctly. The verifiability framework in the previous post applies to LLMs today and will apply to most production AI systems for the foreseeable future.
Second: the investment in alternatives is real and serious. Project Prometheus alone has raised over $16 billion for physical AI. AMI Labs and World Labs have raised over $2 billion for world models. Ineffable Intelligence raised $1.1 billion for reinforcement learning. Safe Superintelligence (SSI), founded by OpenAI co-founder Ilya Sutskever, has raised $3 billion with no product, no revenue, and approximately 20 employees, pursuing what Sutskever describes as "a different path" to superintelligence.23 Thinking Machines Lab, founded by former OpenAI CTO Mira Murati, raised $2 billion in seed funding to build multimodal AI systems.24 Across these six pre-product companies alone, over $24 billion in disclosed or reported funding has been committed to the premise that next-token prediction is not the final answer. And history suggests that the company that ultimately defines the next era may not be the one with the most funding today. OpenAI started with far less than any of these companies. So did Anthropic. Companies building applications that depend on LLM capabilities without any contingency planning for architectural change are taking a risk that is worth acknowledging.
Third: the most useful thing to watch is the domain where each approach performs best. World models will become relevant first in robotics, industrial automation, and physical simulation. Physical AI, as Project Prometheus is pursuing, will become relevant in engineering, manufacturing, and domains that require understanding how materials and objects behave. Reinforcement learning at scale will become relevant where the solution space exceeds human expertise and outcomes can be simulated. SSM hybrids will become relevant first in applications that need very long context windows at scale. Neurosymbolic approaches will become relevant first in domains with explicit rule structures: compliance, formal verification, and structured data reasoning. Causal AI is already in production for decision support at major technology companies. Active inference will matter most for autonomous agents that need to manage their own uncertainty. Diffusion language models may change how text is generated and edited. Large concept models may change the unit of prediction from tokens to ideas.
None of these will replace LLMs in the next two years. All of them are worth tracking.
As Geoffrey Nicholson of 3M once put it: research is the transformation of money into knowledge. Innovation is the transformation of knowledge into money. The $24 billion flowing into these pre-product companies is the first half. What you build with that knowledge is the second.
- TechCrunch, "Yann LeCun's AMI Labs raises $1.03 billion to build world models," March 2026. ↑
- TechCrunch, "World Labs lands $1B, with $200M from Autodesk, to bring world models into 3D workflows," February 2026. ↑
- Yann LeCun, "A Path Towards Autonomous Machine Intelligence," OpenReview, 2022. ↑
- Meta AI, "Introducing V-JEPA 2: Our Next Step Toward Advanced Machine Intelligence," 2025. ↑
- Mahmoud Assran et al., "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning," arXiv:2506.09985, June 2025. ↑
- Albert Gu and Tri Dao, "Mamba: Linear-Time Sequence Modeling with Selective State Spaces," arXiv:2312.00752, 2023. ↑
- MIT-IBM Watson AI Lab, "Neuro-Symbolic AI," research program. ↑
- Przemek Chojecki, "Going Beyond LLMs and Transformers: Emerging Architectures for Efficient Large Language Models in 2026," Medium, December 2025. ↑
- Judea Pearl, "Causality: Models, Reasoning and Inference," Cambridge University Press, 2nd edition, 2009. ↑
- Uber Engineering, "Using Causal Inference to Improve the Uber User Experience," Uber Blog, 2019. ↑
- Karl Friston, "The Free-Energy Principle: A Unified Brain Theory?" Nature Reviews Neuroscience, 11, 127-138, 2010. ↑
- Karl Friston et al., "Active Inference and Artificial Reasoning," arXiv:2512.21129, December 2025. ↑
- VERSES AI, "VERSES Renews Agreement with Chief Scientist Karl Friston to Continue Innovation," December 2024. ↑
- Shen Nie et al., "Large Language Diffusion Models (LLaDA)," arXiv:2502.09992, February 2025. ↑
- "LLaDA-MoE: A Sparse MoE Diffusion Language Model," arXiv, 2025. ↑
- LCM Team et al., "Large Concept Models: Language Modeling in a Sentence Representation Space," Meta AI, arXiv:2412.08821, December 2024. ↑
- Meta AI, "Large Concept Models," research page. ↑
- Marvin Minsky, "A Framework for Representing Knowledge," MIT AI Laboratory Memo 306, 1974. ↑
- TechCrunch, "DeepMind's David Silver just raised $1.1B to build an AI that learns without human data," April 2026. ↑
- David Silver et al., "Mastering the game of Go with deep neural networks and tree search," Nature 529, 484-489, 2016. ↑
- Bloomberg, "Bezos's Project Prometheus AI Lab Hits $38 Billion Valuation After Funding Round," April 2026. ↑
- The Next Web, "Jeff Bezos' physical AI lab is close to raising $10 billion," April 2026. ↑
- TechCrunch, "OpenAI co-founder Ilya Sutskever's Safe Superintelligence reportedly valued at $32B," April 2025. ↑
- TechCrunch, "Mira Murati's Thinking Machines Lab is worth $12B in seed round," July 2025. ↑
Frequently Asked Questions
What architectures are competing with LLMs in 2026?
Ten distinct research directions are addressing different limitations of next-token prediction. The most heavily funded are world models (Meta's V-JEPA 2, AMI Labs, World Labs), reinforcement learning at scale (Ineffable Intelligence), and physical AI (Project Prometheus, $16.2B). The other approaches worth tracking are neurosymbolic AI, state space models like Mamba, causal AI, energy-based models, active inference, diffusion language models, and large concept models. Each addresses a specific weakness: physical grounding, reasoning fragility, quadratic scaling cost, hallucination, or correlation-vs-causation.
What is a world model and how does it differ from an LLM?
A world model predicts what happens next in the physical world rather than what word comes next in a sentence. Yann LeCun's Joint Embedding Predictive Architecture (JEPA) predicts in an abstract representation space, forcing the model to learn structure rather than surface patterns. Meta's V-JEPA 2, trained on more than one million hours of video, can plan robot actions in environments it has never seen, without fine-tuning. The trade-off: world models are not yet competitive with LLMs on language tasks. Their advantage lies in domains where physical grounding matters more than text generation.
How much money has been invested in alternatives to LLMs in 2026?
Across six pre-product companies founded or led by top AI researchers, over $24 billion in disclosed funding has been committed to architectures beyond next-token prediction. Project Prometheus (Bezos) leads at $16.2B for physical AI. Safe Superintelligence (Sutskever) raised $3B. Thinking Machines Lab (Murati) raised $2B. AMI Labs (LeCun) raised $1.03B. World Labs (Fei-Fei Li) raised $1B. Ineffable Intelligence (Silver) raised $1.1B. None has shipped a product. All are betting that LLMs have a structural ceiling.
Continue Reading
Your AI Vendor Claims Their LLM Can Reason. Here's What's Actually Happening.
Every AI vendor claims their LLM can reason. They all run next-token prediction underneath. Here's what that means for the capability claims you trust.
"Reasoning Models" Are Still Just Predicting the Next Token.
OpenAI's o-series, Anthropic's extended thinking, DeepSeek-R1. They're marketed as reasoning models. The training changed. The architecture did not.
Your AI Can't Reason. But You Can Still Get Reliable Results.
AI doesn't need to reason to be reliable. It needs problems with verifiable answers. A four-question framework for where AI works in the enterprise.
Wondering whether to bet on LLMs or wait for what comes next?
We help mid-market companies build AI systems that work today while staying flexible for what comes next. Let's talk about your roadmap.
Let's Talk