Your AI Model Isn't Reasoning. It's Searching.

President, Zaruko
Table of Contents

A new paper from Oxford made headlines in March 2026. An X/Twitter post summarizing it read: "GPT-5.4 Pro made beyond-human progress on two of 100 unsolved math problems."
The claim is technically anchored in the paper. But the framing is misleading in a way that matters. Understanding exactly how is more useful than the headline itself.
The Paper
The research is called HorizonMath.1 It is a benchmark of over 100 unsolved mathematical problems across eight domains, including combinatorics, geometry, number theory, and physics. These are not textbook problems. They are open research questions that the mathematical community has not solved. Because the answers are unknown, the benchmark cannot be contaminated by training data. Any model that produces a correct answer has produced something new.
The evaluation framework is built around a principle the researchers call the generator-verifier gap. A generator-verifier gap (also written generator–verifier gap) exists when solutions to a problem are difficult to produce but easy to check. You may not know the answer to a combinatorics optimization problem, but once a candidate answer is proposed, you can verify whether it is correct by running a deterministic computation. The paper specifically selected problems with this property because it makes automated evaluation possible without human review.
The evaluation pipeline works like this. The model generates a proposed solution, written as a Python function. A compliance checker filters out forbidden approaches, such as numerical approximations presented as exact closed forms. The remaining candidate solutions are routed to one of three evaluation modes: numeric comparison against a known high-precision reference, benchmark scoring against a published baseline, or a deterministic check that the proposed construction satisfies all required properties. Pass or fail.
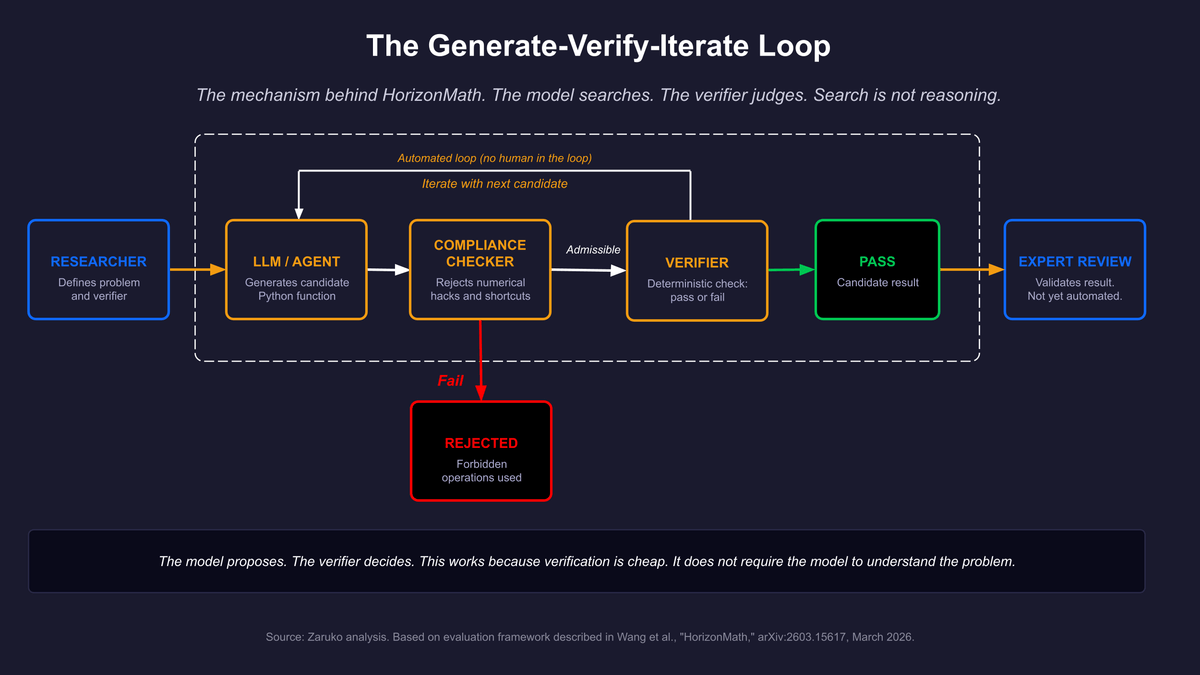
Figure 1: The mechanism behind HorizonMath. The model proposes candidates, a verifier checks them, and the loop continues. This is search, not reasoning.
What Actually Happened
On the unsolved tiers of the benchmark, the only model that produced potentially novel improvements was GPT-5.4 Pro. Gemini 3.1 Pro and Claude Opus 4.6 solved some calibration problems but produced no novel solutions that passed the compliance checker and verifier. GPT-5.4 Pro improved on two problems, both from the solvability 1 tier, meaning the researchers assessed them as likely solvable with near-term capabilities.
Neither improvement was a proof. Neither was a theoretical advance. Both were optimization results.
The first was the Thin-Triangle Kakeya problem. The task was to select 128 intercept values to minimize the area of the union of 128 thin triangles. GPT-5.4 Pro's solution started from a structured seed configuration and then performed local search over the intercept values, iteratively adjusting each one to reduce the total area, running passes to escape local minima. The resulting area was a modest improvement over the previous best. The paper verified this result with exact rational arithmetic.
The second was a Ramsey theory bound. The task was to find coefficients for a correction polynomial that would lower the best-known constant in an upper bound on diagonal Ramsey numbers. GPT-5.4 Pro tried a grid of seed coefficients, evaluated each one against the feasibility conditions, selected the best-performing seed, then iteratively reduced the sum of the coefficients while maintaining feasibility. The result was a small improvement over the previously published bound. The paper labeled both results as "potentially novel contributions, pending expert review." They are not yet accepted mathematical results.
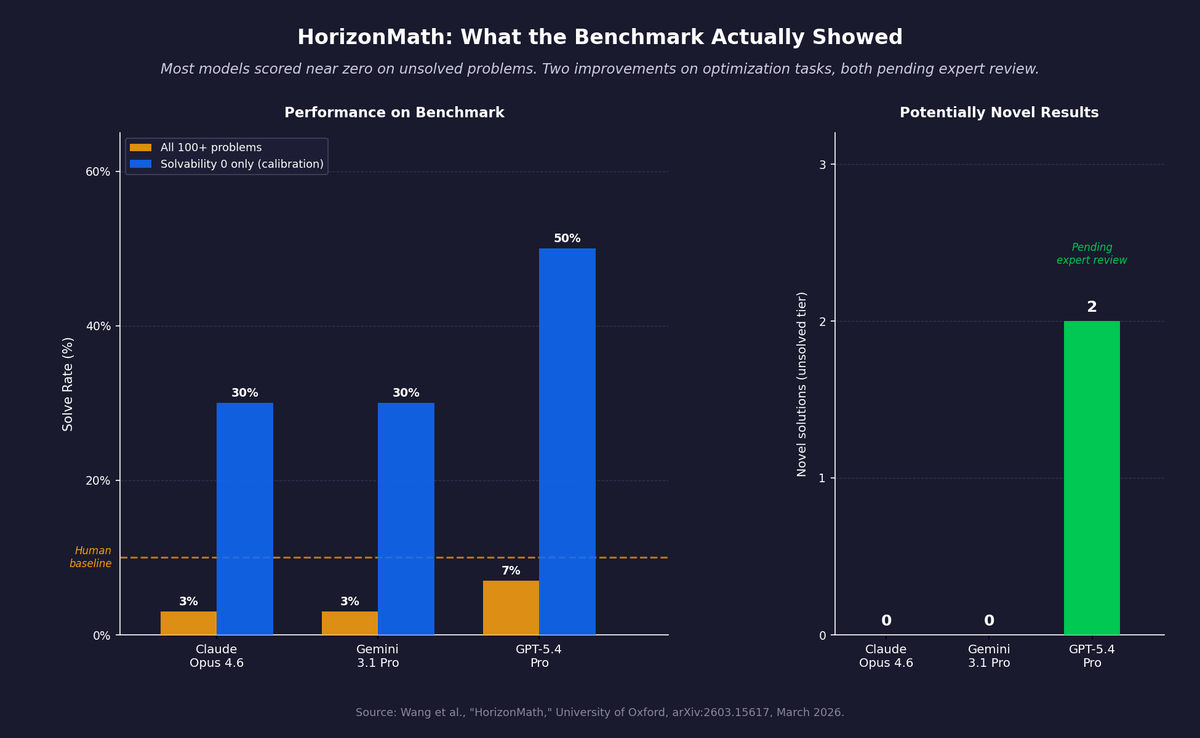
Figure 2: HorizonMath benchmark results. Most models score near zero on unsolved problems. GPT-5.4 Pro improved two optimization-style problems. Both results are pending expert review.
What the Model Was Actually Doing
In both cases the model was not reasoning in the sense of constructing novel logical inferences from first principles, as discussed in the previous post in this series. It was searching.
The Kakeya solution explicitly describes its approach as starting from a seed and then performing local perturbations to escape local minima. That is a search algorithm. The Ramsey solution describes a grid search over seed coefficients followed by iterative refinement. That is also a search algorithm.
What makes this work is precisely the generator-verifier gap the paper describes. Because checking a candidate solution is computationally cheap, the model can generate many candidates quickly, test each one, keep what works, and discard what does not. The model does not need to understand the Kakeya problem in any deep mathematical sense. It needs to propose candidate configurations and have those configurations evaluated.
This is not a new idea. AlphaGo did the same thing in a different domain. A policy network proposed moves. A value function evaluated board positions. Tree search refined the candidates. The game of Go has a generator-verifier gap: generating good moves is hard, but evaluating whether a position is better is tractable. The result was a system that played at a level no human had reached, without the system understanding Go the way a human understands it.
HorizonMath shows the same structure applied to mathematics. The LLM is the policy network, proposing candidate solutions drawn from patterns in its training. The verifier is the evaluation script. The loop between proposal and verification does the work that vendors are calling reasoning.
The Claim That Went Around X/Twitter
The X/Twitter post that sparked this series said GPT-5.4 Pro made "beyond-human progress" on two unsolved math problems after "1 hour of reasoning."
The "1 hour" figure refers to compute time spent generating candidates and running the verification loop. The model is not sitting there thinking. It is running search iterations, each one generating a candidate and checking it against the verifier. The compute time measures the length of the search, not the depth of the thought.
"Beyond-human" is accurate in a narrow sense. Human mathematicians had not published these specific improvements. But the method used, iterative numerical optimization within an existing framework, is not a method that requires deep mathematical insight. It requires patience and compute. The paper itself is careful: it calls the results "potentially novel contributions pending expert review." They are conjectures until proven.
The broader issue is not that the X/Twitter post was lying. It was that it described a search and verification result using language that implies comprehension. Most readers who saw that post came away believing something different from what the paper showed.
The Insight That Actually Matters
The HorizonMath paper is more interesting than the headline suggests. Not because AI can reason, but because of what the generator-verifier gap enables.
If you can frame a problem so that candidate solutions are easy to verify, AI becomes dramatically more useful. You do not need the model to understand the problem at a deep level. You need it to propose candidates that the verifier can test. The more computationally cheap the verification, the more candidates you can test per unit of time, and the more likely you are to find a good one.
This is a structural observation about where AI creates value, and it extends far beyond mathematics. If you can turn your business problem into something that has a verifiable answer, AI can search the space of candidate solutions more quickly than any human team. If you cannot, the model is working with no external feedback loop, and you are relying entirely on its pattern matching to be right.
This pattern is already showing up in practice. In an April 2026 Quanta Magazine profile, Fields Medalist Terence Tao described current AI models as "very good at scouring big lists of problems for low-hanging fruit" while cautioning that the results are "scattered successes among a big sea of unreported failures."2 The same article describes UCLA mathematician Ernest Ryu using ChatGPT to prove a 42-year-old conjecture in optimization theory. Ryu's process followed the same structure: the model proposed candidate proofs, most of them wrong, while Ryu played the role of the verifier, keeping what worked and discarding what did not. "I felt like I was covering a lot of ground very rapidly," Ryu said, "much more quickly than I could do on my own." The model was not doing the mathematics. It was generating candidates for a human verifier.
The question of whether your problem has that structure is one of the most important questions to ask before deploying an AI system. It is related to the same gap we covered in AI Can Write It. It Cannot Think It. The fluency of the output conceals what the model is actually doing underneath. The next post in this series examines what changed in the reasoning models that vendors now sell as different, and what did not. For a look at the same generator-verifier structure applied outside mathematics, see If Mythos Can Break Code, Can It Break Patents?
- Erik Y. Wang et al., "HorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification," University of Oxford, arXiv:2603.15617, March 2026. ↑
- Konstantin Kakaes, "The AI Revolution in Math Has Arrived," Quanta Magazine, April 13, 2026. ↑
Frequently Asked Questions
Is AI actually reasoning, or is it doing something else?
When AI models produce results on hard problems, the mechanism is usually search, not reasoning. The model generates candidate solutions drawn from patterns in its training, then a verifier checks each candidate and keeps the ones that pass. This is the same structure AlphaGo used in Go. It works when verification is cheap, not because the model understands the problem.
What is the generator-verifier gap?
The generator-verifier gap describes problems where solutions are hard to produce but easy to check. A combinatorics optimization is a good example: you may not know the answer, but once a candidate is proposed, you can run a deterministic computation to verify it. This gap is what enables AI to appear to solve hard problems. The model proposes candidates and a cheap verifier filters them.
What did the HorizonMath benchmark actually show about AI and mathematics?
HorizonMath tested frontier AI models on over 100 unsolved mathematics problems. Most models scored near zero on the unsolved tiers. GPT-5.4 Pro improved two problems, both optimization-style, through iterative numerical search. Neither result is a proof or a theoretical advance, and both are labeled 'pending expert review.' The paper demonstrates search with verification, not mathematical reasoning.
Continue Reading
Your AI Can't Reason. But You Can Still Get Reliable Results.
AI doesn't need to reason to be reliable. It needs problems with verifiable answers. A four-question framework for where AI works in the enterprise.
If Mythos Can Break Code, Can It Break Patents?
If AI can find software vulnerabilities at scale, can it design around patent claims? The same generator-verifier structure, applied to a new domain.
Your AI Vendor Claims Their LLM Can Reason. Here's What's Actually Happening.
Every AI vendor claims their LLM can reason. They all run next-token prediction underneath. Here's what that means.
Trying to separate AI capability from AI marketing?
I help mid-market companies evaluate AI claims and identify where AI actually creates business value. Let's talk.
Let's Talk