Your AI Can't Reason. But You Can Still Get Reliable Results.

President, Zaruko
Table of Contents

The first post in this series argued that large language models predict tokens rather than reason. The second showed that inference-time search with a verifier can produce results on hard problems, even without reasoning. The third explained that training-time advances, chain-of-thought and reinforcement learning, improve outputs without changing the underlying architecture.
Now the synthesis: the debate over whether AI can reason is less useful than it looks. The more important question is whether your problem has a structure that lets AI perform reliably without reasoning.
Most high-value problems do. You just have to find the structure.
The Generator-Verifier Gap, Again
A generator-verifier gap exists when producing a good solution to a problem is hard, but checking whether a proposed solution is good is comparatively easy.
Chess has a generator-verifier gap. Generating a strong move requires deep search and evaluation. Evaluating whether a board position is stronger than another is comparatively cheap, even if imperfect. This gap is central to how AlphaGo worked. The system proposed moves, evaluated positions, and searched across possibilities. It did not need to understand chess the way a human grandmaster understands it. It needed to generate candidates and verify results.
HorizonMath, the Oxford benchmark covered in the second post, is built around this idea: progress is measured on research problems where candidate answers can be automatically checked.3 The reported progress occurred in settings where candidate solutions could be evaluated computationally. The problems where AI made no progress were theoretical questions without a defined answer, where there is no automated way to check a proposed answer.
Software has a generator-verifier gap wherever tests exist. If you have a test suite, every proposed code change can be checked automatically. The model generates code. The tests verify it. This is why AI code generation has improved faster than almost any other capability.
Where Enterprise Problems Have This Structure
The pattern appears in more places than it seems at first.
Compliance checking. Where the rules are explicit and machine-checkable, verification can be deterministic. AI can generate candidate documents and revisions. The verifier provides the feedback loop.
Data transformation. The input and output schemas are specified. A proposed transformation either produces correct output or it does not. The verification is deterministic. AI generates candidate transformations, tests confirm them.
Pricing and configuration. Constraints are defined. A proposed price or configuration either satisfies margin requirements, inventory constraints, and policy rules, or it does not. The verification is mechanical.
Contract review for defined criteria. For narrow, explicit criteria, "does this clause contain a limitation of liability?" is a verifiable question. AI can generate an answer. A structured check can verify coverage by reviewing clause types systematically.
Anomaly detection thresholds. Given historical data and a defined metric, a proposed threshold either produces a false-positive rate below the target or it does not. The verification is quantitative.
In all of these cases, you do not need the model to reason about the problem in any deep sense. You need it to generate plausible candidates and have a mechanism to tell you which ones are correct.
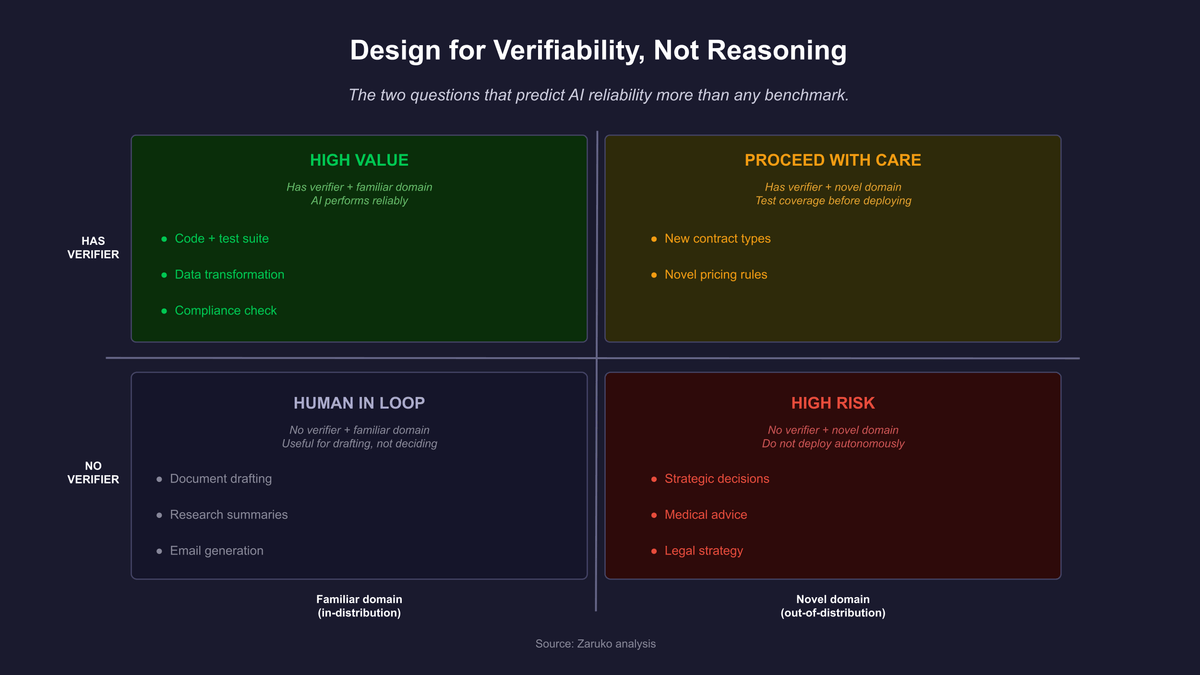
Figure 1: The two questions that predict AI deployment reliability more than any benchmark score.
Where Enterprise Problems Do Not Have This Structure
The problems without a generator-verifier gap are the ones where the definition of "good" requires human judgment in the loop.
Strategic advice. There is no test suite for whether a market entry decision was correct. You can evaluate it in hindsight, but not cheaply or automatically before acting. AI can inform the analysis. It cannot close the loop.
Novel creative work with aesthetic criteria. The definition of good depends on an audience, a context, and a judgment that cannot be fully automated. AI can draft. Verification requires a human.
Relationship-sensitive communication. Whether an email is effective depends on the recipient, the history, the stakes, and dozens of factors that cannot be fully specified. There is no verifier.
Decisions with regulatory liability. Whether a medical recommendation or a legal strategy is correct often cannot be verified computationally. The cost of a wrong answer is asymmetric and the verification requires qualified judgment.
In these domains, AI is useful as a tool for drafting, structuring, and informing. It is not a system you can hand an output to and trust without review. The absence of a verifier means there is no feedback loop, and no feedback loop means errors compound invisibly.
The Practical Framework
Before deploying any AI system in a business context, ask these four questions.
One: can a proposed solution to this problem be checked without human judgment? If yes, you have a verifier. If no, you do not.
Two: how cheap is the verification relative to the generation? The cheaper the verification, the more candidates you can test, and the better the expected output. Automated tests are cheap. Expert review is expensive. Design toward cheap verification wherever possible.
Three: how stable is the mix of problems you encounter? AI performs well in domains it was trained on. If your problems vary widely in framing, your effective verifier needs to cover that variation too. The Apple GSM-Symbolic research, covered in the first post, is the cleanest illustration: a single irrelevant clause in an otherwise familiar math problem can collapse accuracy across every model type tested, including reasoning models.1
Four: what is the cost of a wrong answer that passes the verifier? No verifier is perfect. Some incorrect outputs will pass. The stakes determine how much downstream checking is warranted.
These questions matter more than model benchmarks. For example, a model that scores 90 percent on a reasoning benchmark may perform at 60 percent on your specific problem types. A model that scores 80 percent on the benchmark may perform at 90 percent on your problems if they fall squarely within what it was trained on. The benchmark tells you something about the general capability. The framework above tells you whether that capability transfers.
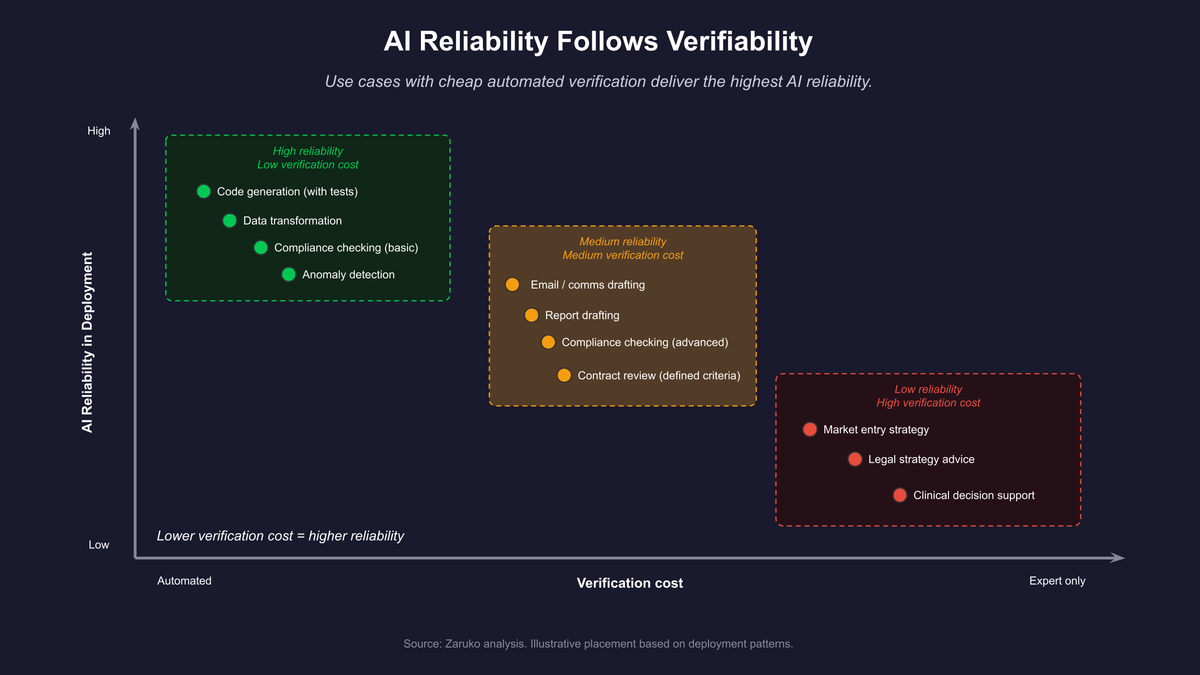
Figure 2: Use cases with cheap automated verification are structurally more likely to deliver reliable AI results. Use cases that require expert judgment to verify produce lower reliability regardless of model quality.
The One Sentence Summary
AI does not need to reason to be useful. It needs a problem that has a verifiable answer and a problem type it has seen before.
Design for that. Not for reasoning.
This post synthesizes results from the prior three posts in the series, listed in the Continue Reading section below. Primary sources are cited in those posts.
- Mirzadeh et al., "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models," Apple Machine Learning Research, ICLR 2025. ↑
- Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS 2022.
- Wang et al., "HorizonMath," University of Oxford, arXiv:2603.15617, 2026. ↑
Frequently Asked Questions
What is the generator-verifier gap and why does it matter for AI?
A generator-verifier gap exists when producing a good solution to a problem is hard, but checking whether a proposed solution is good is comparatively easy. Chess has it: generating a strong move is hard, evaluating a board position is cheaper. Software with tests has it: generating code is hard, running tests is cheap. AI systems perform reliably on problems with this structure because the model can generate candidates and a verifier can confirm which are correct, without the model needing to reason about the problem.
Which enterprise problems can AI handle reliably without reasoning?
Problems with explicit, machine-checkable criteria. Compliance checking where rules are codified. Data transformation where input and output schemas are specified. Pricing and configuration where constraints are defined. Contract review for narrow, explicit clause types. Anomaly detection with quantitative thresholds. In each case, AI generates candidates and a deterministic check confirms correctness. The model doesn't need to understand the domain. It needs a verifier.
What four questions should I ask before deploying AI on a business problem?
One: can a proposed solution be checked without human judgment? If yes, you have a verifier. Two: how cheap is the verification relative to generation? Cheap automated tests beat expensive expert review. Three: how stable is the mix of problems you encounter? AI performs well in domains it was trained on. Four: what is the cost of a wrong answer that passes the verifier? No verifier is perfect, and the stakes determine how much downstream checking is warranted. These questions matter more than benchmark scores.
Continue Reading
"Reasoning Models" Are Still Just Predicting the Next Token.
OpenAI's o-series, Anthropic's extended thinking, DeepSeek-R1. They're marketed as reasoning models. The training changed. The architecture did not.
Your AI Model Isn't Reasoning. It's Searching.
Oxford's HorizonMath benchmark shows AI models improving two unsolved math problems. The improvements came from search, not reasoning.
Your AI Vendor Claims Their LLM Can Reason. Here's What's Actually Happening.
Every AI vendor claims their LLM can reason. They all run next-token prediction underneath. Here's what that means for the capability claims you trust.
Trying to figure out where AI will actually work for your business?
We help mid-market companies identify the problems where AI delivers reliable results, and walk away from the ones where it won't. Let's talk about your use case.
Let's Talk