"Reasoning Models" Are Still Just Predicting the Next Token.

President, Zaruko
Table of Contents

The previous two posts established two things. First: every large language model predicts the next token. There is no separate architectural reasoning module; the model generates text through next-token prediction. Second: some models can improve on verifiable optimization problems by combining that token prediction with a search-and-verify loop.
Now for the question that follows naturally: what about the models sold explicitly as reasoning models? OpenAI's o-series. Anthropic's extended thinking. DeepSeek-R1. These are marketed as different, and they do perform better on many tasks. So what changed?
The answer is: the training changed. The architecture did not.
This distinction matters more than most AI coverage suggests.
What Chain-of-Thought Training Actually Does
Chain-of-thought prompting was introduced by researchers at Google in 2022.1 The original paper showed that prompting a model to write out intermediate steps before giving a final answer improved accuracy on math and logic problems. The gains were striking. Prompting a 540-billion-parameter model with eight worked examples achieved the best-published results on a grade-school math benchmark, outperforming models that had been specifically fine-tuned on math.
The reason it works is mechanical, not cognitive. When a model generates intermediate steps, those steps become additional tokens in the context window. The model then predicts the final answer token using a context that now includes worked steps, not just the original question. The additional tokens provide more information to condition the prediction on. The output improves because the input to the final prediction step is richer, not because the model has developed the ability to reason.
The analogy that makes this concrete: imagine asking someone a hard question in an exam. If they can write in the margins, they tend to get better answers. Not because the margins contain reasoning that would not otherwise occur, but because externalizing intermediate thoughts frees up working memory and prevents compounding early errors. The margins do not change what kind of thinker you are. They change how much of your thinking is visible and available to inform subsequent steps. Chain-of-thought does the same thing for a language model.
What Reasoning Model Training Actually Does
The vendors selling reasoning models went further than prompting. They trained on chain-of-thought. DeepSeek-R1 is the most technically open case because the research team published a detailed technical report.2
DeepSeek-R1 was trained using reinforcement learning applied directly to the base model. The training process works like this. The model generates a candidate answer. The answer is checked against a verifiable ground truth, either a correct mathematical result or a passing code test. If the answer is correct, the model receives a positive reward signal and those generation patterns are reinforced. If the answer is wrong, the patterns are suppressed. Over many iterations, the model learns to generate longer, more structured response sequences that are more likely to produce correct final answers.
This is a meaningful training advance. DeepSeek-R1 achieves performance comparable to OpenAI o1 on math and coding benchmarks, at a fraction of the cost. The approach works because verifiable tasks, math problems with exact answers and code with test cases, provide clean reward signals. When you can define correct automatically, reinforcement learning can run at scale.
But notice what this is. It is the same generator-verifier structure from the HorizonMath post, applied at training time rather than inference time. The model is rewarded for outputs that pass a verifier. The verifier is a math checker or a code executor. The model learns which patterns of token generation tend to produce outputs that pass. Those patterns are then encoded in the weights.
The architecture of the base model is unchanged. It still predicts the next token. What changed is which patterns produce high rewards during training, and therefore which patterns the model has learned to favor.

Figure 1: What CoT and RL fine-tuning do and do not change. Training improves performance in familiar domains. The underlying mechanism, and its limits, remain.
What This Training Has Not Eliminated
The Apple GSM-Symbolic paper, discussed in the first post in this series, is directly relevant here.3 The paper tested frontier models including models trained with chain-of-thought. The finding held across all of them. Adding a single irrelevant clause to a math problem caused significant accuracy drops across all model types, including models sold as reasoning models. The gap narrowed in stronger models, but it did not disappear. The authors found no evidence of formal reasoning in any model tested.
This is not surprising once you understand the mechanism. Chain-of-thought training teaches the model to generate longer structured responses that follow the pattern of worked solutions. That pattern is itself learned from training data. When the input differs from that pattern, because an irrelevant clause disrupts the expected structure, the learned pattern fails. The model has not learned to reason about problem structure. It has learned to generate text that looks like reasoning about problem structure.
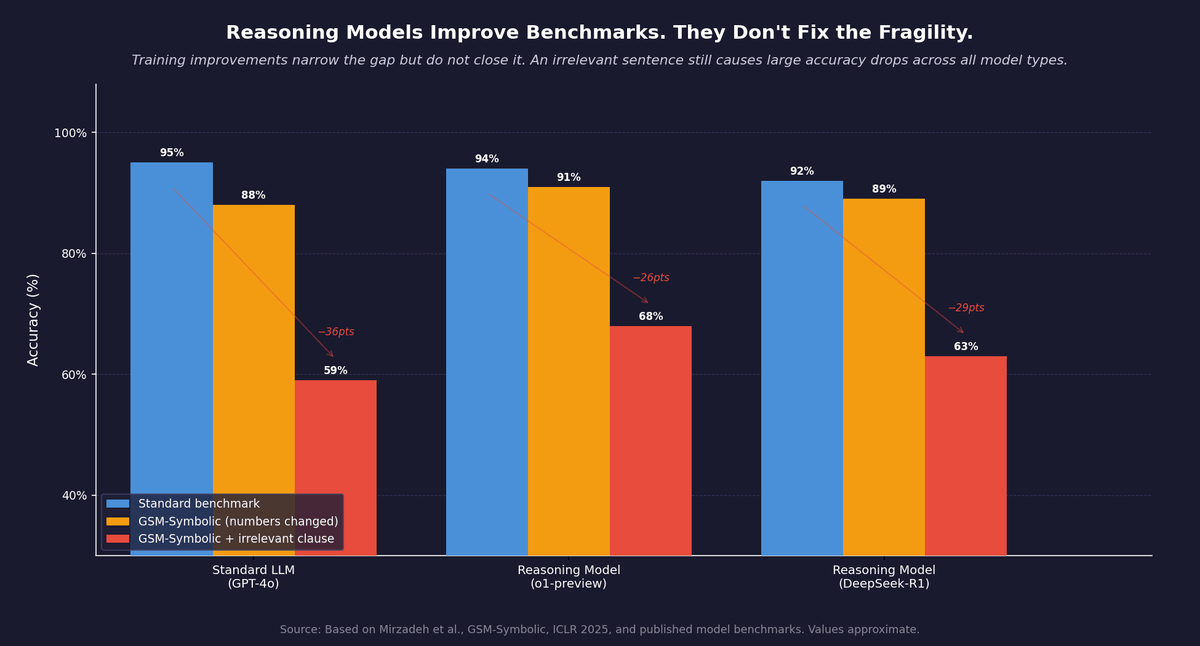
Figure 2: Reasoning model training narrows the fragility gap but does not close it. An irrelevant sentence still causes large accuracy drops across all model types. Based on Mirzadeh et al., GSM-Symbolic, ICLR 2025. Values approximate.
The distinction has a practical consequence. A model trained on math reasoning will perform well on math problems that look like its training data. It will perform less well on math problems that look structurally different, even if the underlying mathematics are identical. A reasoning model does not generalize across surface variation the way a human reasoner does.
What This Means in Practice
None of this is an argument against using reasoning models. For tasks where the structure is predictable and the distribution is similar to the training data, reasoning model performance is substantially better than standard models. The improvements are real and measurable.
The argument is about calibration.
When a vendor says their model is a reasoning model, what they mean is that it has been trained on chain-of-thought data and reinforcement learning on verifiable tasks, and it performs well on benchmarks that measure that training. It does not mean the model reasons in the way a trained professional reasons. It does not mean performance will hold when the framing of the problem changes. It does not mean the model will catch errors that arise from surface-level distractors.
The question to ask before deploying a reasoning model is not whether the benchmark numbers are good. The question is whether your use case looks like what the model was trained on. If your problems have verifiable answers and predictable structure, reasoning model performance will likely transfer. If your problems involve novel framings, ambiguous criteria, or high sensitivity to irrelevant context, you are in the territory where the pattern-matching limits become most visible.
The next post synthesizes this. The practical question is not whether AI reasons. It is whether your problem has the structure that lets AI perform reliably without reasoning.
- Jason Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," Google Brain, NeurIPS 2022. ↑
- DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," January 2025. ↑
- Mirzadeh et al., "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models," Apple Machine Learning Research, ICLR 2025. ↑
Frequently Asked Questions
Are reasoning models like OpenAI o-series and DeepSeek-R1 architecturally different from regular LLMs?
No. Reasoning models use the same underlying architecture as standard LLMs. Every output is still produced by predicting the next token. What changed is the training. Reasoning models are fine-tuned on chain-of-thought data and reinforcement learning on verifiable tasks like math problems and code, which teaches them to generate longer, more structured response sequences. The architecture is unchanged.
What does chain-of-thought training actually do to a language model?
Chain-of-thought training teaches the model to produce intermediate steps before the final answer. Those steps become additional tokens in the context window, giving the model richer input to condition the final prediction on. The analogy is writing in the margins of an exam: the margins do not change what kind of thinker you are, but externalizing intermediate work frees up working memory and prevents compounding early errors. The model has not learned to reason. It has learned to generate text that looks like reasoning.
When should enterprises use reasoning models?
Reasoning models perform substantially better than standard LLMs on tasks with predictable structure and distributions similar to their training data, especially problems with verifiable answers like math and code. They struggle when problems have novel framings, ambiguous criteria, or high sensitivity to irrelevant context. Apple's GSM-Symbolic research showed that even reasoning models drop significantly in accuracy when a single irrelevant clause is added to a math problem. Ask whether your use case looks like what the model was trained on, not just whether the benchmark numbers are good.
Continue Reading
Your AI Can't Reason. But You Can Still Get Reliable Results.
AI doesn't need to reason to be reliable. It needs problems with verifiable answers. A four-question framework for where AI works in the enterprise.
Your AI Model Isn't Reasoning. It's Searching.
Oxford's HorizonMath benchmark shows AI models improving two unsolved math problems. The improvements came from search, not reasoning.
Your AI Vendor Claims Their LLM Can Reason. Here's What's Actually Happening.
Every AI vendor claims their LLM can reason. They all run next-token prediction underneath. Here's what that means.
Calibrating how much to trust your reasoning model?
I help mid-market companies separate what AI actually does from how AI is marketed. Let's talk about your use case.
Let's Talk